
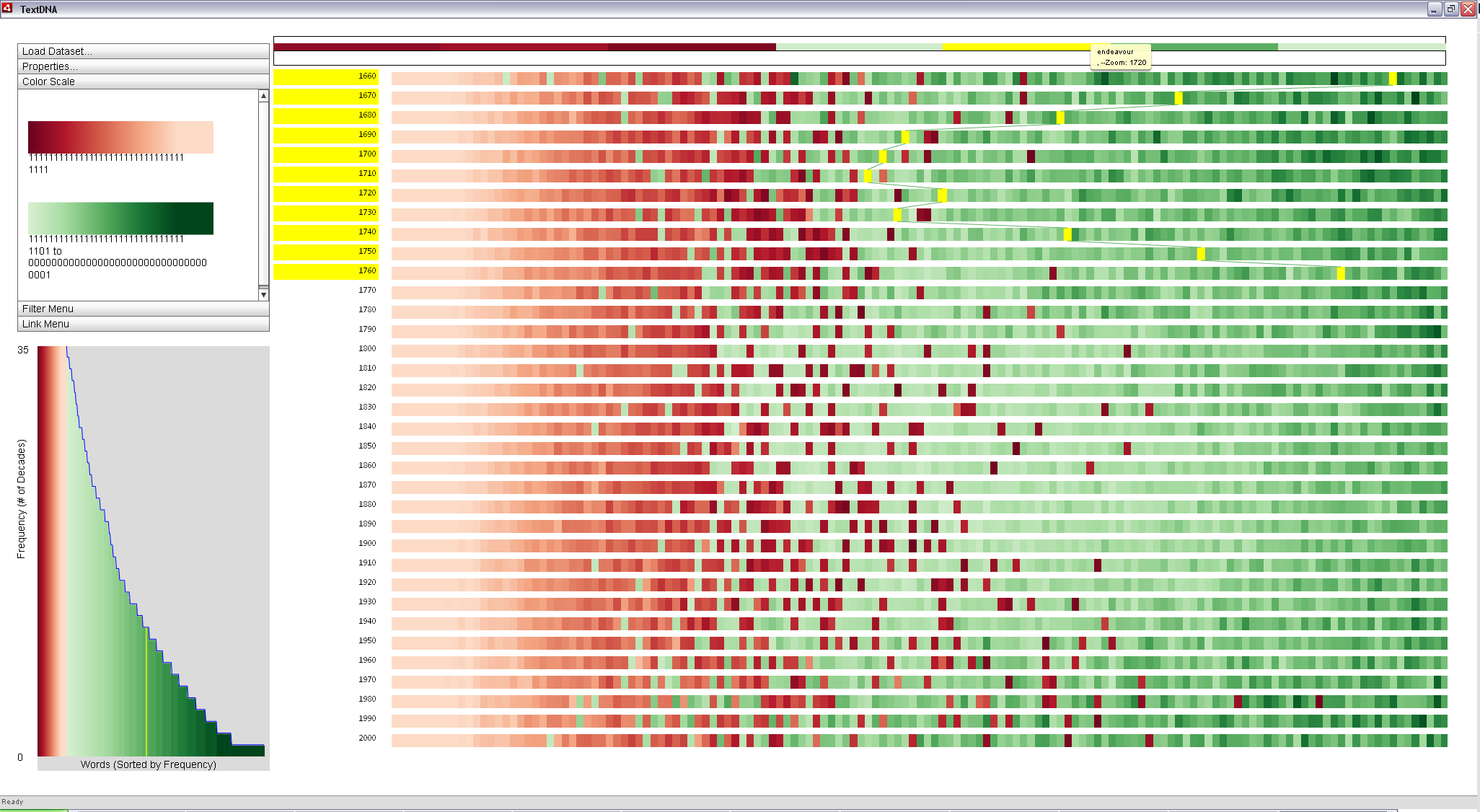
TextDNA leverages the design of the Sequence Surveyor system to support large-scale overview analysis of patterns in linguistic data. TextDNA supports the comparison of ordered sets of linguistic data by visualizing the sequences as colored rows and elements within the set as colored blocks within each row. Subsequences within the sequences can also be defined and are displayed from largest to smallest within each set row. Patterns between matching elements, as defined by the dataset, can be explored by interacting with the display. The sample datasets found below contains the top 1,000 and 5,000 words per decade since 1660 according to the Google N-Grams dataset. TextDNA is also compatible with CSV files. For examples of how to use TextDNA with the sample dataset, visit the Getting Started Guide. For detailed information on how to use the system, please see the User's Guide.
TextDNA Software Package: TextDNA_0_5.air
TextDNA Sample Database: top_1000.db, top_5000.db
Plays from Shakespeare: Wordcount CSV Files
Dataset Generator (Python 2.7): Dataset Generation Script and Instructions
TextDNA Getting Started Guide: Getting Started
TextDNA Instructions for use: User's Guide
Changes in Version 0.5:
- New default color settings.
- Fixed bugs with connections and with "Number of Matches" computation using multiple CSVs.
- Linked words are now editable in the grid.
- Display settings persist across dataset changes.
- Links now work with non-numeric set names.
- Supplemental data from databases corrected.
- Zoom window details now correspond to only the selected zoomed block.
Project Page | Sequence Surveyor | TextDNA
Adobe AIR must be installed to run Sequence Surveyor and TextDNA.
Email dalbers@cs.wisc.edu for more information.