This is an old version of the page!
Please refer to https://pages.graphics.cs.wisc.edu/BoxerDocs/ for a more recent and complete version.
Boxer: Interactive Comparison of Classification Results
Boxer is a system for comparing the results of machine learning classifiers. Please see the EuroVis 2020 paper for a description. This site has a brief introduction, videos, an online demo, and the beginnings of a user guide.
The Boxer system is available open source. The source repository is on GitHub. However, if you just want to use the system, the demo is available online.
Boxer is still under active development. The original system (available here) focuses on comparing discrete choice classifiers by identifying subsets of instances where the performance is interesting. We are in the process of extending Boxer to handle other types of machine learning problems, such as probabilistic classification and regression. We are also trying to make the system easier to use through documentation and a guidance system.
The beginnings of the User Guide is available on this site.
To cite boxer:
Michael Gleicher, Aditya Barve, Xinyu Yu, and Florian Heimerl. Boxer: Interactive Comparison of Classifier Results. Computer Graphics Forum 39 (3), June 2020. DOI:10.1111/cgf.13972
Official journal web page (the paper is open access!): https://diglib.eg.org/handle/10.1111/cgf13972
Motivation
Machine learning practitioners often perform experiments that compare classification results. Users gather the results of different classifiers and/or data perturbations on a collection of testing examples. Results data are stored and analyzed for tasks such as model selection, hyper-parameter tuning, data quality assessment, fairness testing, and gaining insight about the underlying data. Classifier comparison experiments are typically evaluated by summary statistics of model performance, such as accuracy, F1, and related metrics. These aggregate measures provide for a quick summary, but not detailed examination. Examining performance on different subsets of data can provide insights into the models (e.g., to understand performance for future improvement), the data (e.g., to understand data quality issues to improve cleaning), or the underlying phenomena (e.g., to identify potential causal relationships). Making decisions solely on aggregated data can lead to missing important aspects of classifier performance. To perform such closer examination, practitioners rely on scripting and existing tools in their standard workflows. The lack of specific tooling makes the process laborious and comparisons challenging, limiting how often experiments are examined in detail.
Main Contribution
Boxer is a comprehensive approach for interactive comparison of machine learning classifier results. It has been implemented in a prototype system. We show how Boxer enables users to perform a variety of tasks in assessing machine learning systems.
Innovations
-
The approach to classifier comparison that combines subset identification, metric selection, and comparative visualization to enable detailed comparison in classifier results.
-
The architecture of multiple selections and set algebra that allows users to flexibly link views and specify data subsets of interest.
-
Interactive techniques and visual designs that make the approach practical. These key ideas should be applicable in other systems for interactive comparison within complex data.
Example of Boxer System
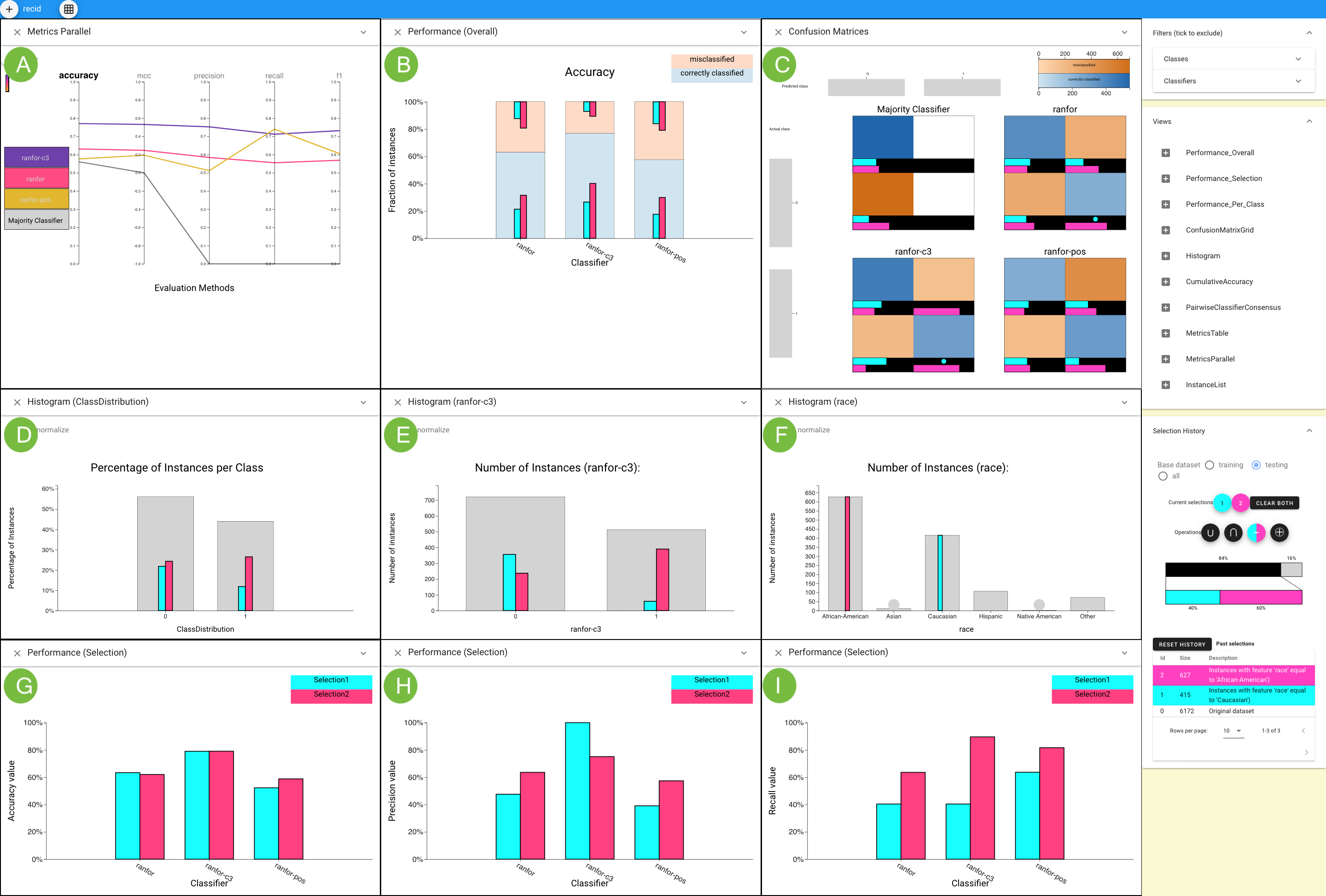 This figure shows how Boxer’s flexible mechanisms can be used to predict whether a person will commit a crime within two years based on the data set contains 6,172 instances. Parallel Metrics view (A) shows the C3 classifier has better performance by all metrics. A histogram of race (F) selects Caucasian (cyan) and African-American (pink) instances. The Overall Performance view (B) shows C3’s overall higher precision, but a lack of overlap with cyan. The Confusion Matrix (C) Grid view shows many false positives for African-Americans and many false negatives for Caucasians for C3. Histograms show the distribution of selected sets across the actual (D) and the C3-predicted class (E). The Performance Selection views in the third line compare accuracy (G) , precision (H) , and recall (I) for C3 on the subsets.
This figure shows how Boxer’s flexible mechanisms can be used to predict whether a person will commit a crime within two years based on the data set contains 6,172 instances. Parallel Metrics view (A) shows the C3 classifier has better performance by all metrics. A histogram of race (F) selects Caucasian (cyan) and African-American (pink) instances. The Overall Performance view (B) shows C3’s overall higher precision, but a lack of overlap with cyan. The Confusion Matrix (C) Grid view shows many false positives for African-Americans and many false negatives for Caucasians for C3. Histograms show the distribution of selected sets across the actual (D) and the C3-predicted class (E). The Performance Selection views in the third line compare accuracy (G) , precision (H) , and recall (I) for C3 on the subsets.
Demo (Submission) Video
Acknowledgements
This work was in part supported by NSF award 1830242 and DARPA FA8750-17-2-0107.