TextDNA: GUI Overview

Display Overview
TextDNA leverages multiple visual displays to support visual analysis. The above image is the default TextDNA screen that appears when first loading a dataset. The components are as follows:
- Primary Display: An overview display of the data. Sequences map to rows; elements map to colors within the rows.
- Zoom Window: A detailed view of a specific blocked region within a row as selected by the user.
- Label Bar: The names of the sequences represented by each row. Names are aligned with the sequence rows that they represent.
- Histogram: A distribution of the matching sets of elements by frequency within the data. Elements are sorted along the x-axis according to the number of elements in the matching set and colored with respect to the color parameters of the primary display. The height of an element bar represents the average frequency of the element sets represented by the bar.
- Navigation Pane: This panel contains a variety of options for interacting with and exploring the data in the primary display.
Navigation Pane
Aggregation Type
TextDNA offers two block encodings which display different statistical properties of the colors of the elements represented by the block.
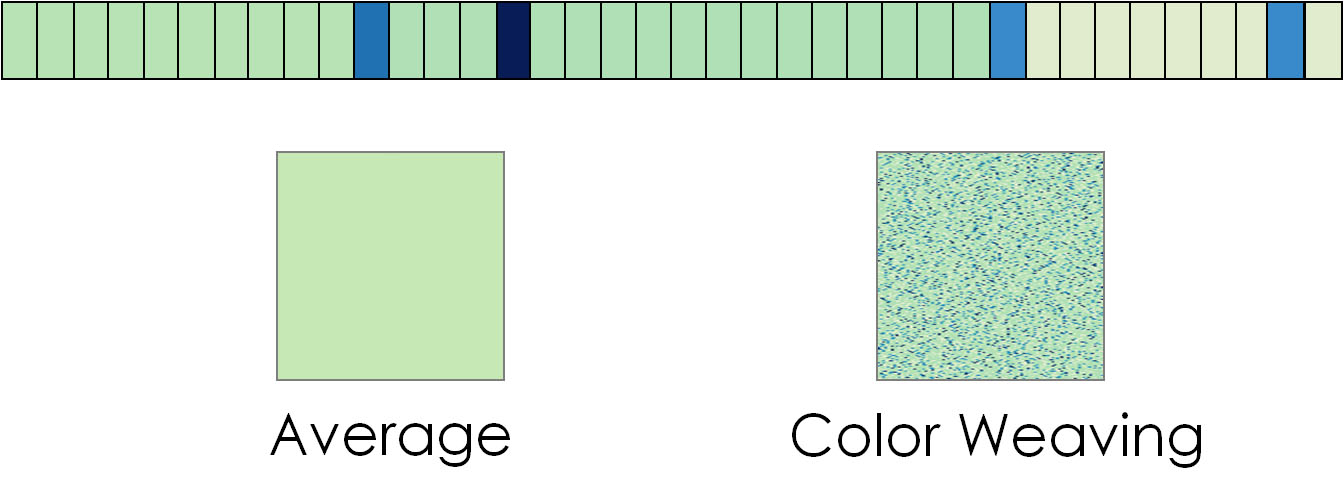
- Averaging: Each block in the sequences of the display pane is represented as a solid color representing the average value of the "Color By" parameter across elements in the block.
- Color Weaving: Each block represents the approximate distribution of values of the "Color By" parameters across elements in the block. Each pixel is mapped to the value of one element. After each element is mapped to a pixel, the elements are randomized and mapped to the remaining pixels. The randomization repeats until the block is filled.
Color By
This list defines the property of an element that is mapped to the element color. There are five default property colorings. "Sequence Co-Occurrence" and "Rank In Reference" are split coloring properties: a portion of the elements are mapped to one ramp while the remainder are mapped to another. They require you to choose the primary "Color Scheme" and "Secondary Ramp."
- Word Rank: the ordinal position of a word in a sequence; for raw text, it is the reading order position within the collection; for ranked text, it is the relative commonality of the word in the collection
- Word Frequency: how often the word appears in the dataset as a whole; for raw text, it is the number of instances of the word within the corpus; for ranked text, it is the number of sequences the word appears in
- Sequence Co-Occurrence: the specific set of sequences that a word occurs in
- Rank in Reference: colors elements in a dataset according to their color scheme in a specific sequence
- count: the frequency of each word within the the raw text of the underlying corpus
- tag: optional, user-specified input for text-tagging
- tfidf: colors data according to the importance of a word to the corpus (adjusts for the fact certain words occur more frequently than others (e.g., stop words) in a corpus; the tfidf value increases according to the number of times a word is used in a documet yet offsets by the frequency of the word in the overall corpus.
Order By
This menu section contains parameter settings for the ordering of elements within a Sequence. TextDNA provides four ordering options.
- Word Rank: the ordinal position of a word in a sequence; for raw text, it is the reading order position within the collection; for ranked text, it is the relative commonality of the word in the collection
- Word Frequency: how often the word appears in the dataset as a whole; for raw text, it is the number of instances of the word within the corpus; for ranked text, it is the number of sequences the word appears in
- Sequence Co-Occurrence: the specific set of sequences that a word occurs in
- Word Count: the frequency of each word within the the raw text of the underlying corpus
Match On
This menu selection specifies behavior in the display pane, specifically indicating how you wish to compare elements across sequences upon mouseover of element blocks. Options are Word, Rank, Frequency, Sequence Co-Occurrence, and Count.
Color Scheme
This dropdown contains color ramps that are mapped to elements. By default, TextDNA offers a variety of sequential and diverging color ramps, along with a greyscale.

Secondary Ramp
This dropdown is used to specify the secondary color ramps used when using split color encodings. If the same ramp is specified in the "Color Scheme" and "Secondary Ramp," split encodings will use the first half of the ramp as the "Color Scheme" and the second half as the "Secondary Ramp." The ramps are the same as those offered in the "Color Scheme" list.
Preset Configurations
This menu selection applies common Order By and Color By configurations. Presets are named for the type of data the configurations allow users to explores.
- Co-Occurrence of Ordered Words
- Color By: Word Rank & Order By: Sequence Co-Occurrence
- For seeing word usage patterns in an entire dataset
- Term order for Common Words
- Color By: Sequence Co-Occurrence & Order By: Word Rank
- For seeing what the most common words are and where they sequentially occur.
- Frequency of Ordered Words
- Color By: Word Frequency & Order By: Word Rank
- For seeing the most popular words within each sequence in relation to their popularity in the dataset as a whole.
- Frequency of Co-Occurring Words:
- Color By: Word Frequency & Order By: Sequence Co-Occurrence
- For seeing the popularity of the most common words in the dataset.
Words To Highlight
Entering a word or list of words separated by commas in this box and pressing enter will de-emphasize blocks where input words do not occur, leaving blocks with words matching input bright.
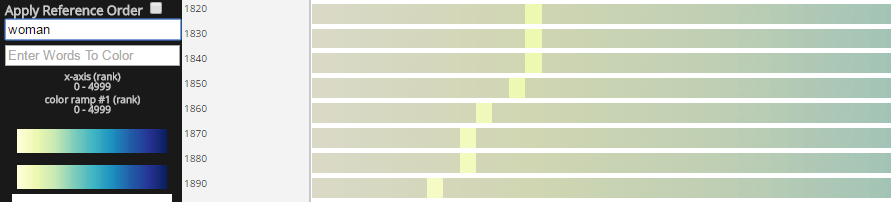
Words To Color
Entering a word or list of words separated by commas in this box and pressing enter will transform the color blocks with words that do not match input to grey, and map a contrasting color to blocks/pixels with words matching input.

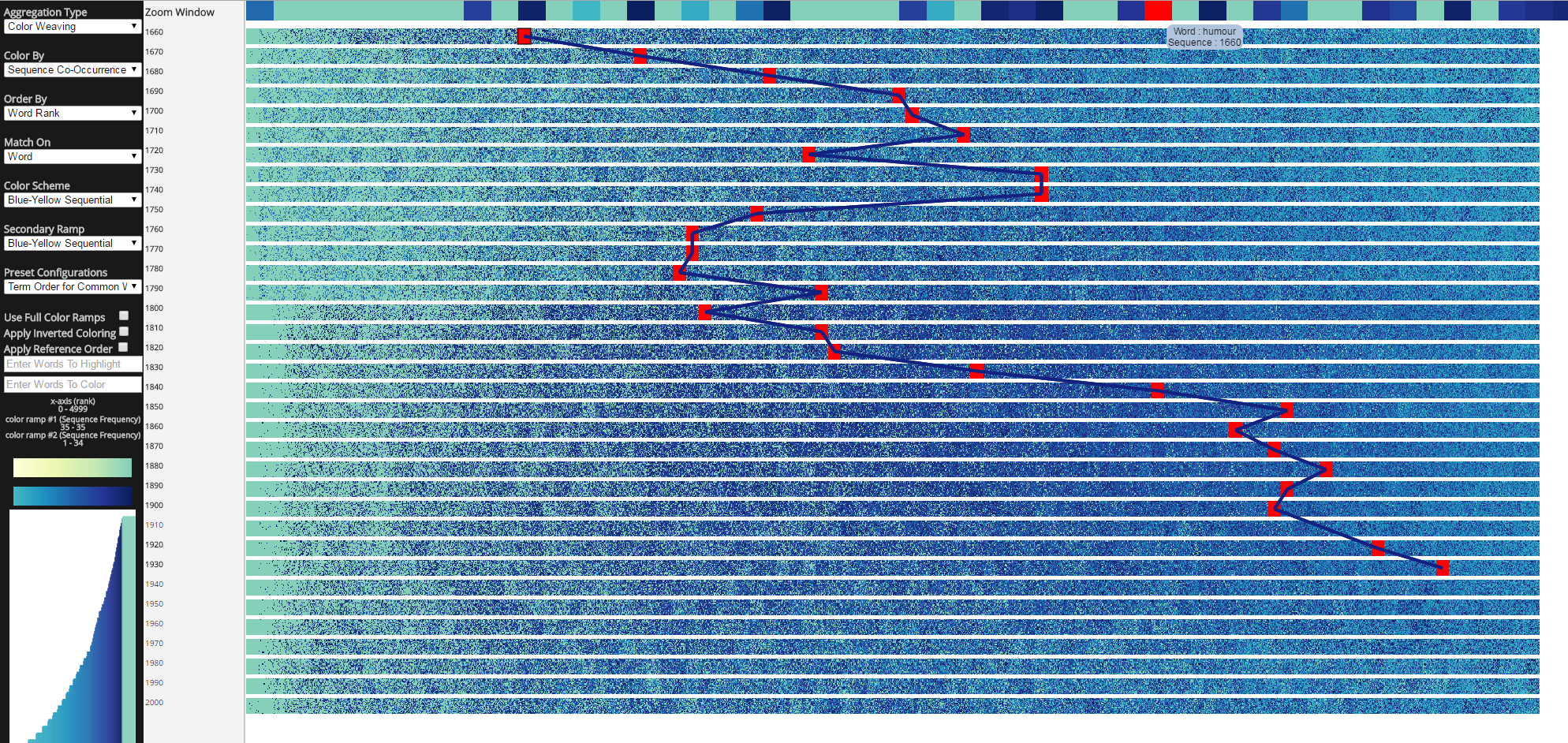
Zoom Window
Left clicking on a block in the display pane shows the elements represented by the block in the zoom window.

You can interact with the elements in the zoom window by hovering over them.

If you left click on a word in the zoom window, TextDNA maps the behavior of the element across sequences. Here is the behavior of the word "humour."
Right-Click Behavior
Right-clicking on a block within a sequence provides several ways to interact with the GUI:
 |
|
Show Words
Selecting Show Words from the right-click menu generates a window that allows you to explore words within a block and their related data properties.

Email danielle.szafir@colorado.edu for more information.